반응형
※ 분석하기 좋은 데이터란?
분석하기 좋은 데이터란 데이터 집합을 분석하기 좋은 상태로 만들어 놓은 것을 말한다. 데이터 분석 단계에서 데이터 정리는 아주 중요하다. 실제로 데이터 분석 작업의 70% 이상을 차지하고 있는 작업이 데이터 정리 작업이다. 분석하기 좋은 데이터는 다음 조건을 만족해야 하며 이 조건을 만족하는 데이터를 깔끔한 데이터(Tidy Data)라고 부른다.
▶ 깔끔한 데이터의 조건
- 데이터 분석 목적에 맞는 데이터를 모아 새로운 표(Table)를 만들어야 한다.
- 측정한 값은 행(row)을 구성해야 한다.
- 변수는 열(column)로 구성해야 한다.
※ 데이터 연결 기초
1. concat 메서드로 데이터 연결하기
import pandas as pd
row_concat = pd.concat([df1, df2, df3])
print(row_concat)
2. 연결한 데이터프레임에서 행 데이터 추출하기
print(row_concat.iloc[3,])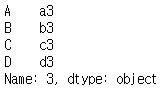
3. 데이터프레임에서 시리즈 연결하기
new_row_series = pd.Series(['n1', 'n2', 'n3', 'n4'])
4. concat 메서드로 데이터프레임과 시리즈로 연결하기
print(pd.concat([df1, new_row_series]))
시리즈가 새로운 행으로 추가된 것이 아니라, 새로운 열로 추가된다.
※ 행이 1개라도 반드시 데이터프레임에 담아 연결해야 한다.
시리즈에는 열 이름이 없기 때문에 새로운 행으로 연결하려고 하면 제대로 연결되지 않는다. 그래서 시리즈를 새로운 열로 간주하여 0이라는 이름의 열로 추가한다.
1. 1개의 행을 가지는 데이터프레임을 생성하여 df1에 연결하기
new_row_df = pd.DataFrame([['n1', 'n2', 'n3', 'n4']], columns = ['A', 'B','C', 'D'])
print(new_row_df)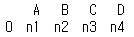
2. append 메서드를 이용하여 데이터 연결하기
연결할 데이터프레임이 1개라면 append 메서드를 사용해도 된다.
print(df1.append(new_row_df))
3. append 메서드와 딕셔너리를 사용하여 데이터 연결하기
ignore_index를 True로 설정하면 데이터를 연결한 다음 데이터프레임의 인덱스를 0부터 다시 지정한다.
data_dict = {'A' : 'n1', 'B' :'n2', 'C' : 'n3', 'D':'n4'}
print(df1.append(data_dict, ignore_index = True))
※ 다양한 방법으로 데이터 연결하기
1. 열 방향으로 데이터 연결하기
col_concat = pd.concat([df1, df2, df3], axis = 1)
print(col_concat)
2. 데이터프레임에서 열 이름으로 데이터를 추출하면 해당 열 이름의 데이터를 모두 추출한다.
print(col_concat['A'])
3. 새로운 열 추가하기
col_concat['new_col_list'] = ['n1', 'n2', 'n3', 'n4']
print(col_concat)
4. ignore_index를 True로 지정하여 열 이름을 다시 지정하기
nt(pd.concat([df1, df2, df3], axis = 1, ignore_index = True))
※ 공통 열과 공통 인덱스만 연결하기
1. 열 이름의 일부가 서로 다른 데이터프레임을 연결하기
df1.columns = ['A', 'B', 'C', 'D']
df2.columns = ['E', 'F', 'G', 'H']
df3.columns = ['A', 'C', 'F', 'H']
print(df1)
print(type(df1))
2. 새롭게 열 이름을 부여한 데이터프레임 3개를 concat 메서드로 연결하기
row_concat = pd.concat([df1, df2, df3])
print(row_concat)
3. 데이터프레임의 공통 열만 골라 누락값없이 연결하기.
print(pd.concat([df1, df2, df3], join = 'inner'))
4. df1, df3의 공통 열만 골라서 연결하기
print(pd.concat([df1, df3], ignore_index = False, join = 'inner'))
5. 데이터프레임을 행 방향으로 연결하기 (df1, df2, df3의 인덱스를 다시 지정)
df1.index = [0,1,2,3]
df2.index = [4,5,6,7]
df3.index = [0,2,5,7]
print(df1)
print(df2)
print(df3)
6. concat 메서드로 df1, df2, df3을 행 방향으로 연결하기
col_concat = pd.concat([df1, df2, df3], axis = 1)
print(col_concat)
7. df1, df3의 공통 행만 골라서 연결하기
print(pd.concat([df1, df3], axis = 1, join = 'inner'))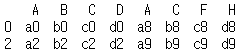
※ 데이터 연결 마무리 (merge 메서드 사용하기)
1. 특정 위치의 날씨 정보에 필요한 데이터 집합 불러오기
person = pd.read_csv('../data/survey_person.csv')
site = pd.read_csv('../data/survey_site.csv')
survey = pd.read_csv('../data/survey_survey.csv')
visited = pd.read_csv('../data/survey_visited.csv')
print(site)
print(visited)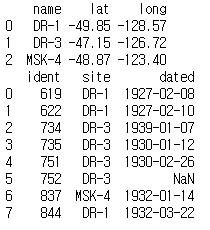
2. merge 메서드는 기본적으로 내부 조인을 실행하며 메서드를 사용한 데이터프레임(site)을 왼쪽으로 지정하고 첫 번째 인잣값으로 지정한 데이터프레임(visited_subset)을 오른쪽으로 지정한다. left_on, right_on 인자는 값이 일치해야 할 왼쪽과 오른쪽 데이터프레임의 열을 지정한다. 즉, 왼쪽 데이터프레임(site)의 열(name)과 오른쪽 데이터프레임(visited)의 열(site)의 값이 일치하면 왼쪽 데이터프레임을 기준으로 연결한다.
m2o_merge = site.merge(visited, left_on = 'name', right_on = 'site')
print(m2o_merge)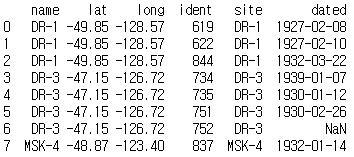
left_on, right_on에 전달하는 값은 여러 개라도 상관없다.
ps_vs = ps.merge(vs, left_on=['ident', 'taken', 'quant', 'reading'],
right_on=['person', 'ident', 'quant', 'reading'])
Reference
 |
|
반응형

댓글