판다스의 데이터프레임과 시리즈는 리스트나 딕셔너리와 달리 많은 양의 데이터를 저장할 수 있을 뿐만 아니라 스프레드시트 프로그램을 사용하는 것처럼 행과 열 단위로 원하는 데이터를 조작할 수 있는 다양한 속성과 메서드를 제공한다.
※ 시리즈 다루기 - 기초
판다스의 데이터를 구성하는 가장 기본 단위는 시리즈이다. 이번에는 데이터프레임에서 시리즈를 선택하는 방법에 대해 알아본다.
(1) 먼저 변수 scientists에 데이터프레임을 준비한다.
scientists = pd.DataFrame(
data={'Occupation': ['Chemist', 'Statistician'],
'Born': ['1920-07-25', '1876-06-13'],
'Died': ['1958-04-16', '1937-10-16'],
'Age': [37, 61]},
index=['Rosaline Franklin', 'William Gosset'],
columns=['Occupation', 'Born', 'Died', 'Age']
)
(2) 데이터프레임에서 시리즈를 선택하려면 loc 속성에 인덱스를 전달하면 된다.
first_row = scientists.loc['William Gosset']
print(first_row)
1. 시리즈 속성과 메서드 사용하기 - index, values, keys
(1) index 속성 사용하기
print(first_row.index)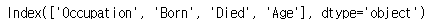
(2) values 속성 사용하기
print(first_row.values)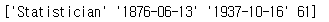
(3) keys 메서드 사용하기
print(first_row.keys())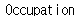
2. 시리즈의 기초 통계 메서드 사용하기
시리즈에는 keys 메서드 외에도 다양한 메서드가 있다.
print(ages.mean())
print(ages.min())
print(ages.max())
print(ages.std())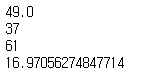
▶ 시리즈 메서드 정리
| 시리즈 메서드 | 설명 |
| append | 2개 이상의 시리즈 연결 |
| describe | 요약 통계량 계산 |
| drop_duplicates | 중복값이 없는 시리즈 반환 |
| equals | 시리즈에 해당 값을 가진 요소가 있는지 확인 |
| get_values | 시리즈에 값 구하기(values 속성과 동일) |
| isin | 시리즈에 포함된 값이 있는지 확인 |
| min | 최솟값 반환 |
| max | 최댓값 반환 |
| mean | 산술 평균 반환 |
| median | 중간값 반환 |
| replace | 특정 값을 가진 시리즈 값을 교체 |
| sample | 시리즈에서 임의의 값을 반환 |
| sort_values | 값을 정렬 |
| to_frame | 시리즈를 데이터프레임으로 변환 |
※ 시리즈 다루기 - 응용
1. 시리즈와 불린 추출
앞 장에서는 원하는 데이터를 추출할 때 특정 인덱스를 지정하여 추출하였다. 하지만 보통은 추출할 데이터의 정확한 인덱스를 모르는 경우가 더 많다. 이런 경우에 사용하는 방법이 불린 추출이다. 불린 추출은 특정 조건을 만족하는 값만 추출할 수 있다.
평균 나이보다 나이가 많은 사람의 데이터를 추출하기
print(ages[ages > ages.mean()])
print(ages > ages.mean())
리스트 형태로 참이나 거짓을 담아 시리즈에 전달하면 참인 인덱스의 데이터만 추출할 수 있다. 이것을 불린 추출이라고 한다.
manual_bool_values = [True, True, False, False, True, True, False, True]
print(ages[manual_bool_values])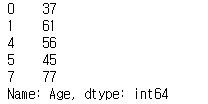
2. 시리즈와 브로드캐스팅
시리즈나 데이터프레임에 있는 모든 데이터에 대해 한 번에 연산하는 것을 브로드캐스팅이라고 한다. 그리고 시리즈처럼 여러 개의 값을 가진 데이터를 벡터라하고 단순 크기를 나타내는 데이터를 스칼라라고 한다.
(1) 같은 길이의 벡터로 곱하기 연산을 수행
print(ages * ages)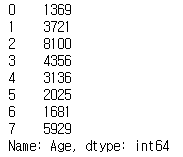
(2) 벡터에 스칼라 연산 수행
print(ages + 100)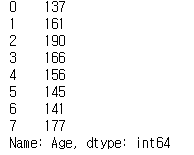
※ 시리즈와 데이터프레임의 데이터 처리하기
(1) 열의 자료형 바꾸기와 새로운 열 추가하기
날짜를 문자열로 저장한 데이터는 시간 관련 작업을 할 수 있도록 datetime 자료형으로 바꿔주는 것이 더 좋다.
born_datetime = pd.to_datetime(scientists['Born'], format='%Y-%m-%d')
print(born_datetime)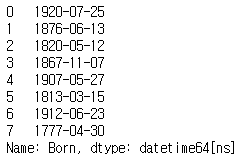
(2) 데이터프레임에 각각의 값을 새로운 열로 추가한다.
scientists['born_dt'], scientists['died_dt'] = (born_datetime, died_datetime)
print(scientists.head())
(3) died_dt 열에서 born_dt를 빼면 과학자가 얼마 동안 세상을 살다가 떠났는지 계산할 수 있다.
scientists['age_days_dt'] = (scientists['died_dt'] - scientists['born_dt'])
print(scientists)
(4) 시리즈, 데이터프레임의 데이터 섞기
가끔은 데이터를 적당히 섞어야 하는 경우도 있다.
print(scientists['Age'])
(5) Age 열의 데이터를 섞으려면 random 라이브러리를 불러와야 한다. random 라이브러리에는 데이터를 섞어주는 shuffle 메서드가 있다. shuffle 메서드에 Age 열을 전달하여 데이터를 섞는다.
import random as rd
rd.seed(42)
rd.shuffle(scientists['Age'])
print(scientists['Age'])
Reference
 |
|

댓글