Pandas는 데이터프레임과 시리즈라는 자료형과 데이터 분석을 위한 다양한 기능을 제공하는 파이썬 라이브러리이다.
또한, 판다스는 파이썬 언어만 사용할 줄 알아도 데이터 분석을 바로 시작할 수 있을 뿐만 아니라 반복되는 데이터 분석 작업을 프로그램으로 만들어 쉽게 해결할 수 있다는 장점이 있다.
※ 데이터 집합 불러오기
1. 데이터 분석의 시작은 데이터 불러오기부터
갭마인더(Gapminder) 데이터를 불러옵니다.
import pandas as pd
df = pd.read_csv('../data/gapminder.tsv', sep='\t')read_csv 메서드는 기본적으로 쉼표로 열이 구분되어 있는 데이터를 불러온다. 하지만 갭마인더는 열이 탭으로 구분되어 있기 때문에 sep 속성값으로 \t를 지정해준다.
2. 시리즈와 데이터프레임
판다스는 데이터를 효율적으로 다루기 위해 시리즈와 데이터프레임이라는 자료형을 사용한다. 데이터프레임은 엑셀에서 볼 수 있는 시트(sheet)와 동일한 개념이며 시리즈는 시트의 열 1개를 의미한다.
head( ) 메서드는 데이터프레임에서 가장 앞에 있는 5개의 행을 출력한다.
print(df.head())

데이터프레임은 자신이 가지고 있는 데이터의 행과 열의 크기에 대한 정보를 shape라는 속성에 저장하고 있다.
1번째 값은 행의 크기이고 2번째 값은 열의 크기이다.
print(df.shape)
shape 속성을 사용했던 것처럼 columns 속성을 사용하면 데이터프레임의 열 이름을 확인할 수 있다.
print(df.columns)
※ 데이터 추출하기
1. 열 단위 데이터 추출하기
데이터프레임에서 데이터를 열 단위로 추출하려면 대괄호와 열 이름을 사용해야 한다. 이때 열 이름은 꼭 작은따옴표를 사용해서 지정해야 하고 추출한 열은 변수에 저장해서 사용할 수도 있다. 이때 1개의 열만 추출하면 시리즈를 얻을 수 있고 2개 이상의 열을 추출하면 데이터프레임을 얻을 수 있다.
데이터프레임에서 열 이름이 country인 열을 추출하여 country_df에 저장
country_df = df['country']
print(country_df.head())
리스트에 열 이름을 전달하면 여러 개의 열을 한번에 추출할 수 있다.
subset = df[['country', 'continent', 'year']]
print(subset.head())
2. 행 단위 데이터 추출하기
데이터를 행 단위로 추출하려면 loc, iloc 속성을 사용해야 한다.
| 속성 | 설명 |
| loc | 인덱스를 기준으로 행 데이터 추출 |
| iloc | 행 번호를 기준으로 행 데이터 추출 |
print(df.loc[0])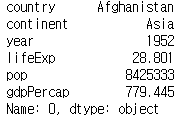
마지막 행 데이터 추출하기
print(df.tail(n=1))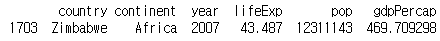
iloc 속성은 음수를 사용해도 데이터를 추출할 수 있다. 다음은 -1을 전달하여 마지막 행 데이터를 추출한 것이다.
print(df.iloc[-1])
3. loc, iloc 속성 자유자재로 사용하기
loc, iloc 속성을 좀 더 자유자재로 사용하려면 추출할 데이터의 행과 열을 지정하는 방법을 알아야 한다. 두 속성 모두 추출할 데이터의 행을 먼저 지정하고 그런 다음 열을 지정하는 방법으로 데이터를 추출한다. 즉, df.loc[[행], [열]] 이나 df.iloc[[행], [열]]과 같은 방법으로 코드를 작성하면 된다.
이때 행과 열을 지정하는 방법은 슬라이싱 구문을 사용하는 방법과 range 메서드를 사용하는 방법이 있다.
(1) 슬라이싱 구문으로 데이터 추출하기
subset = df.loc[:, ['year', 'pop']]
print(subset.head())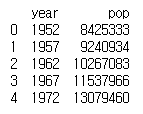
(2) range 메서드로 데이터 추출하기
range 메서드는 지정한 범위의 정수 리스트를 반환하는 것이 아니라 제네레이터를 반환한다. iloc 속성은 제네레이터로 데이터 추출을 할 수 없다. 다행히 제네레이터는 리스트로 변환할 수 있어 iloc의 열 지정값에 전달된다.
small_range = list(range(0, 6, 2))
subset = df.iloc[:, small_range]
print(subset.head())
그런데 실무에서는 range 메서드보다는 간편하게 사용할 수 있는 파이썬 슬라이싱 구문을 더 선호한다. range 메서드가 반환한 제네레이터를 리스트로 변환하는 등의 과정을 거치지 않아도 되기 때문이다.
※ 그래프 그리기
그래프와 같은 데이터의 시각화는 데이터 분석 과정에서 가장 중요한 요소 중 하나이다.
(1) 먼저 그래프와 연관된 라이브러리를 불러온다.
#matplotlib inline
import matplotlib.pyplot as plt
(2) year 열을 기준으로 그룹화한 데이터프레임에서 lifeExp 열만 추출하여 평균값을 구한다.
global_yearly_life_expectancy = df.groupby('year')['lifeExp'].mean()
print(global_yearly_life_expectancy)
(3) 과정 2에서 구한 값에 plot 메서드를 사용하면 다음과 같은 그래프가 나타난다.
global_yearly_life_expectancy.plot()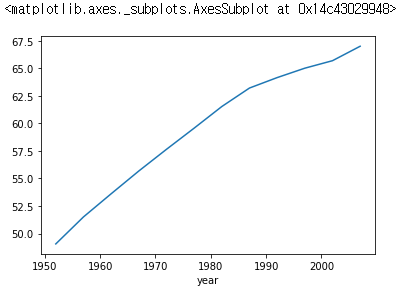
Reference
 |
|

댓글